ps -mp 2289 -o THREAD,tid,time
printf "%x\n" tid
jstack pid |grep tid -A 30
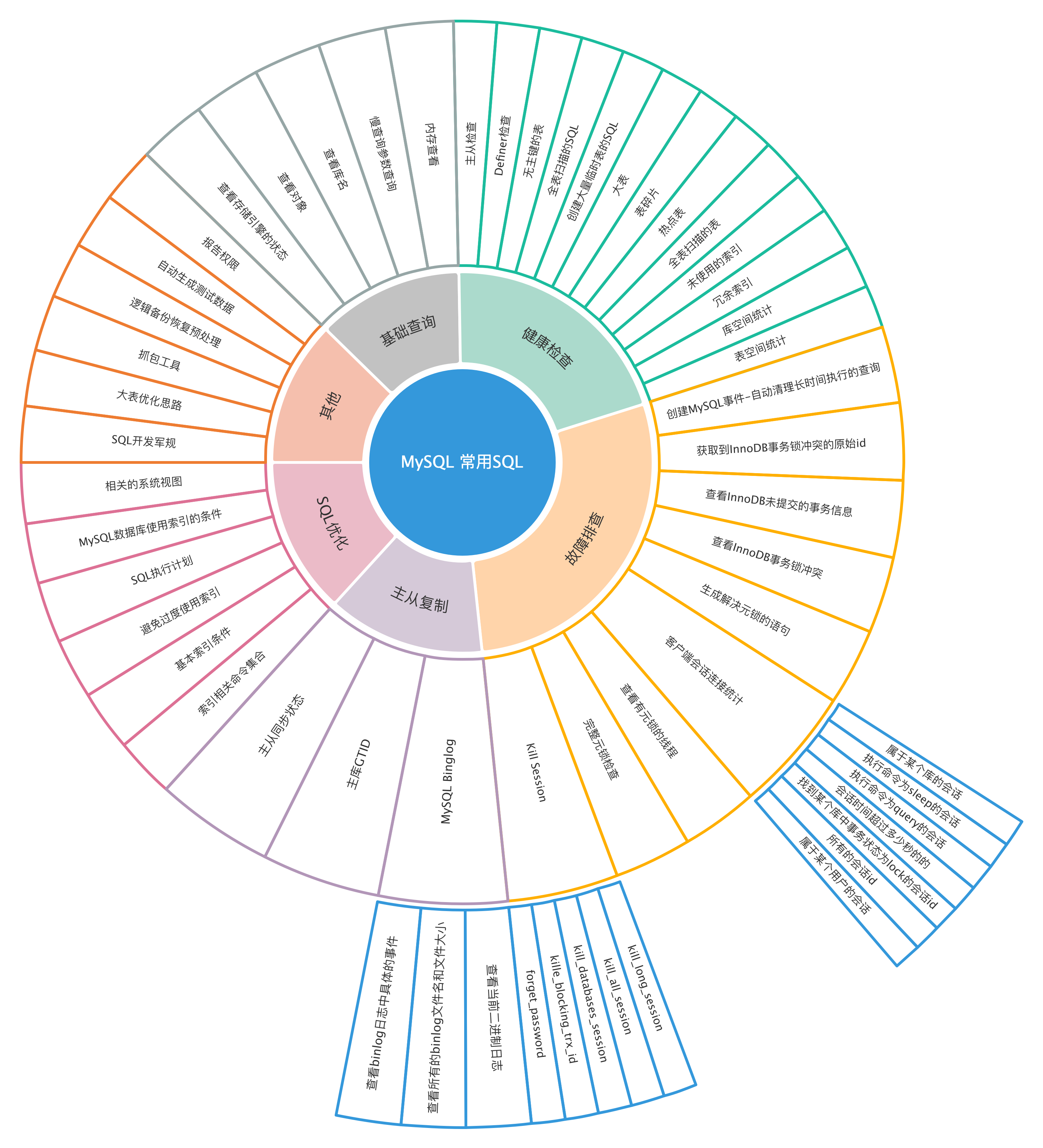
select * from information_schema.processlist where State='Waiting for table metadata lock';
select a.count, b.id
from
(select count(*) count from information_schema.processlist where State='Waiting for table metadata lock') a
join
(
select max(id) id from
(select i.trx_mysql_thread_id id from information_schema.innodb_trx i,
(select
id, time
from
information_schema.processlist
where
time = (select
max(time)
from
information_schema.processlist
where
state = 'Waiting for table metadata lock'
and substring(info, 1, 5) in ('alter' , 'optim', 'repai', 'lock ', 'drop ', 'creat'))) p
where timestampdiff(second, i.trx_started, now()) > p.time
and i.trx_mysql_thread_id not in (connection_id(),p.id)
union select 0 id) t1
)b;
select i.trx_mysql_thread_id from information_schema.innodb_trx i,
(select
id, time
from
information_schema.processlist
where
time = (select
max(time)
from
information_schema.processlist
where
state = 'Waiting for table metadata lock'
and substring(info, 1, 5) in ('alter' , 'optim', 'repai', 'lock ', 'drop ', 'creat'))) p
where timestampdiff(second, i.trx_started, now()) > p.time
and i.trx_mysql_thread_id not in (connection_id(),p.id);
SELECT
a1.ID,
a1.USER,
a1.HOST,
a1.DB,
a1.COMMAND,
a1.TIME,
a1.STATE,
IFNULL(a1.INFO, '') INFO,
a3.trx_id,
a3.trx_state,
unix_timestamp(a3.trx_started) trx_started,
IFNULL(a3.trx_requested_lock_id, '') trx_requested_lock_id,
IFNULL(a3.trx_wait_started, '') trx_wait_started,
a3.trx_weight,
a3.trx_mysql_thread_id,
IFNULL(a3.trx_query, '') trx_query,
IFNULL(a3.trx_operation_state, '') trx_operation_state,
a3.trx_tables_in_use,
a3.trx_tables_locked,
a3.trx_lock_structs,
a3.trx_lock_memory_bytes,
a3.trx_rows_locked,
a3.trx_rows_modified,
a3.trx_concurrency_tickets,
a3.trx_isolation_level,
a3.trx_unique_checks,
IFNULL(a3.trx_foreign_key_checks, '') trx_foreign_key_checks,
IFNULL(a3.trx_last_foreign_key_error, '') trx_last_foreign_key_error,
a3.trx_adaptive_hash_latched,
a3.trx_adaptive_hash_timeout,
a3.trx_is_read_only,
a3.trx_autocommit_non_locking,
a2.countnum
FROM
(SELECT
min_blocking_trx_id AS blocking_trx_id,
COUNT(trx_mysql_thread_id) countnum
FROM
(SELECT
trx_mysql_thread_id,
MIN(blocking_trx_id) AS min_blocking_trx_id
FROM
(SELECT
a.trx_id,
a.trx_state,
b.requesting_trx_id,
b.blocking_trx_id,
a.trx_mysql_thread_id
FROM
information_schema.innodb_lock_waits AS b
LEFT JOIN information_schema.innodb_trx AS a ON a.trx_id = b.requesting_trx_id) AS t1
GROUP BY trx_mysql_thread_id
ORDER BY min_blocking_trx_id) c
GROUP BY min_blocking_trx_id) a2
JOIN
information_schema.innodb_trx a3 ON a2.blocking_trx_id = a3.trx_id
JOIN
information_schema.processlist a1 ON a1.id = a3.trx_mysql_thread_id;
select * from information_schema.innodb_locks;
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
cat /proc/cpuinfo| grep "cpu cores"| uniq
cat /proc/cpuinfo| grep "processor"| wc -l
SELECT table_name,table_rows,data_length,index_length,(data_length+index_length) data FROM information_schema.tables where table_schema='vingoo_ms' ;
select sum(total_GB) total_GB
from
(select sum(data_length_GB) total_GB from (select table_name,
(round(data_length/1024/1024/1024,2) + round(index_length/1024/1024/1024,2) )as data_length_GB
from information_schema.`tables` where table_schema = "vingoo_ms") t1)t2;
vmstat 1 5
iostat -dkx 1 5
netstat -nat | awk '{print $6}'| sort | uniq -c
netstat -na | grep ESTABLISHED|awk '{print $5}' | awk -F: '{print $1}' | sort|uniq -c
ps -aux 2> /dev/null | sort -k3nr | head -n 5 | awk 'BEGIN{print "%CPU\tPID\tCOMMAD"}{print $3,'\t',$2,'\t',$11}'
ps -aux 2> /dev/null | sort -k4nr | head -n 5 | awk 'BEGIN{print "%MEM\tPID\tCOMMAD"}{print $4,'\t',$2,'\t',$11}'
select version();
show global status like 'Uptime';
show global status like 'Questions';
show global status like 'Threads_connected';
select table_schema,round(sum(data_length/1024/1024),2) as data_length_MB,
round(sum(index_length/1024/1024),2) as index_length_MB
from information_schema.tables
group by table_schema order by data_length_MB desc,index_length_MB desc;
select table_schema,table_name,table_rows,round(data_length/1024/1024,2) as data_length_MB,
round(index_length/1024/1024,2) as index_length_MB
from information_schema.tables
where table_schema = and table_name in ();
select table_schema,table_name, TABLE_ROWS,
round(data_length/1024/1024,2) as data_length_MB,
round(index_length/1024/1024,2) as index_length_MB
from information_schema.tables
order by data_length_MB desc,index_length_MB desc
limit 10;
select count(table_name) table_count from information_schema.tables
WHERE table_type = 'BASE TABLE';
SELECT table_type ,engine,COUNT(TABLE_NAME) AS num_tables
FROM INFORMATION_SCHEMA.TABLES
group by TABLE_TYPE,engine order by num_tables desc;
SELECT
ROUND(((data_size + index_size) / gb),4) AS total_size_gb,
ROUND((index_size / gb),4) AS index_size_gb,
ROUND((data_size / gb),4) AS data_size_gb,
ROUND((index_size / (data_size + index_size)),2) * 100 AS perc_index,
ROUND((data_size / (data_size + index_size)),2) * 100 AS perc_data
FROM (
SELECT
SUM(data_length) data_size,
SUM(index_length) index_size,
SUM(if(engine = 'innodb', data_length, 0)) AS innodb_data_size,
SUM(if(engine = 'innodb', index_length, 0)) AS innodb_index_size,
SUM(if(engine = 'myisam', data_length, 0)) AS myisam_data_size,
SUM(if(engine = 'myisam', index_length, 0)) AS myisam_index_size,
POW(1024, 3) gb
FROM information_schema.tables
WHERE table_type = 'BASE TABLE') a;
SELECT
ROUND((SUM(innodb_index_size + innodb_data_size) / gb),4) AS innodb_total_size_gb,
ROUND((innodb_data_size / gb),4) AS innodb_data_size_gb,
ROUND((innodb_index_size / gb),4) AS innodb_index_size_gb,
ROUND(innodb_index_size / (innodb_data_size + innodb_index_size),2) * 100 AS innodb_perc_index,
ROUND(innodb_data_size / (innodb_data_size + innodb_index_size),2) * 100 AS innodb_perc_data,
ROUND(innodb_index_size / index_size,2) * 100 AS innodb_perc_total_index,
ROUND(innodb_data_size / data_size,2) * 100 AS innodb_perc_total_data
FROM (
SELECT
SUM(data_length) data_size,
SUM(index_length) index_size,
SUM(if(engine = 'innodb', data_length, 0)) AS innodb_data_size,
SUM(if(engine = 'innodb', index_length, 0)) AS innodb_index_size,
SUM(if(engine = 'myisam', data_length, 0)) AS myisam_data_size,
SUM(if(engine = 'myisam', index_length, 0)) AS myisam_index_size,
POW(1024, 3) gb
FROM information_schema.tables
WHERE table_type = 'BASE TABLE') a;
SELECT
ROUND((SUM(myisam_index_size + myisam_data_size) / gb),4) AS myisam_total_size_gb,
ROUND((myisam_data_size / gb),4) AS myisam_data_size_gb,
ROUND((myisam_index_size / gb),4) AS myisam_index_size_gb,
ROUND(myisam_index_size / (myisam_data_size + myisam_index_size),2) * 100 AS myisam_perc_index,
ROUND(myisam_data_size / (myisam_data_size + myisam_index_size),2) * 100 AS myisam_perc_data,
ROUND(myisam_index_size / index_size,2) * 100 AS myisam_perc_total_index,
ROUND(myisam_data_size / data_size,2) * 100 AS myisam_perc_total_data
FROM (
SELECT
SUM(data_length) data_size,
SUM(index_length) index_size,
SUM(if(engine = 'innodb', data_length, 0)) AS innodb_data_size,
SUM(if(engine = 'innodb', index_length, 0)) AS innodb_index_size,
SUM(if(engine = 'myisam', data_length, 0)) AS myisam_data_size,
SUM(if(engine = 'myisam', index_length, 0)) AS myisam_index_size,
POW(1024, 3) gb
FROM information_schema.tables
WHERE table_type = 'BASE TABLE') a;
[root@toberoot ~]# mysql -e "select column_name from information_schema.columns where table_name='vg_sales_alipay';" | awk '{if (NR>1){a=$1;printf("%s,\n", $1)}}'
trade_no_vingoo,
trade_no_alipay,
brand_id,
trade_type,
trade_status,
total_fee,
price,
amount,
refund_fee,
refund_status,
refund_times,
refund_date,
refund_type,
refund_desc,
refund_op,
trade_subject,
trade_body,
gmt_create,
gmt_payment,
buyer_email,
buyer_id,
date_add,
apply_re_fee,
apply_re_desc,
apply_re_op,
apply_re_tag,
apply_re_date,
|